POD发生OOM后的处理策略决策-ADR
[POD发生OOM后的处理策略决策-ADR]
背景
目前运行的java服务发生OutOFmemoryError后POD会卡9分钟才能自行恢复,在这个过程会导致服务整体稳定性影响。运维架构希望这个9分钟能降低到2分钟内。
选项分析
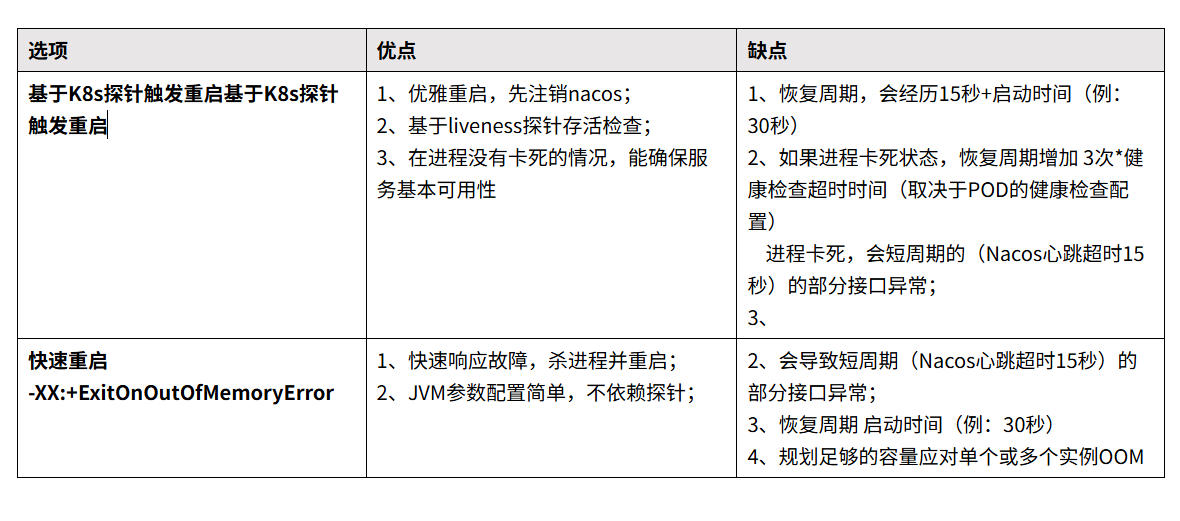
1、基于K8s探针触发重启基于K8s探针触发重启
发生OOM后,服务不会主动停止进程,通过Thread.uncaughtException 机制,监听OOM异常并 将异常信息标记到Actuator的liveness健康检查端点。K8s存活探针检查到liveness 500后,触发Pod重启。
2、快速重启 -XX:+ExitOnOutOfMemoryError
配置好JVM参数,发生OOM 触发oom脚本执行,退出当前JVM进程,POD因主进程停止而触发crash重启。
决策
选择[快速重启]
生产发生OOM大概率是在导出 场景这种场景会一直load数据到内存,可能出现服务卡顿加上持续并发接口情况,使用快速杀死进程方式断臂求生,也是快速响应的方式。
当服务触发ExitOnOutOfMemoryError 会有回调脚本触发,回调脚本优先调用shutdown接口来确保nacos注册服务下线,可以将不可用影响降低至1秒级内.
PS:实际验证在30QPS的情况下,2000个请求,发生OOM 会有1-3个请求失败的情况。
后果
1、故障期间一定会产生 低于50%的请求15秒时长的不可用,由于请求的命中随机性,可能用户端感受是80%-90%不可用;
2、能够快速响应OOM故障;
3、需要规划足够的冗余服务数量减少影响概率;
 关注微信公众帐号
关注微信公众帐号